 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Deep Model Reference Adaptive Control
Aug 04, 2021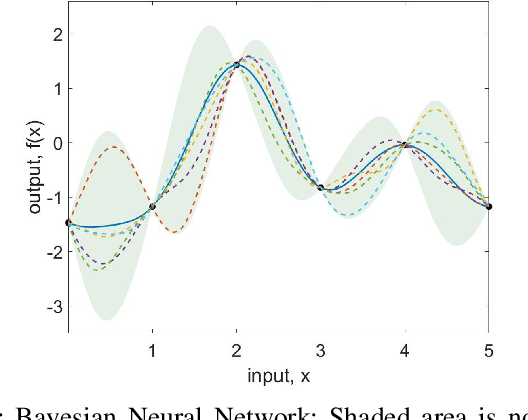
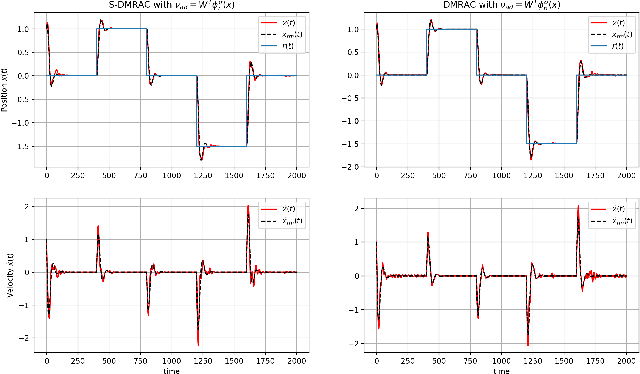
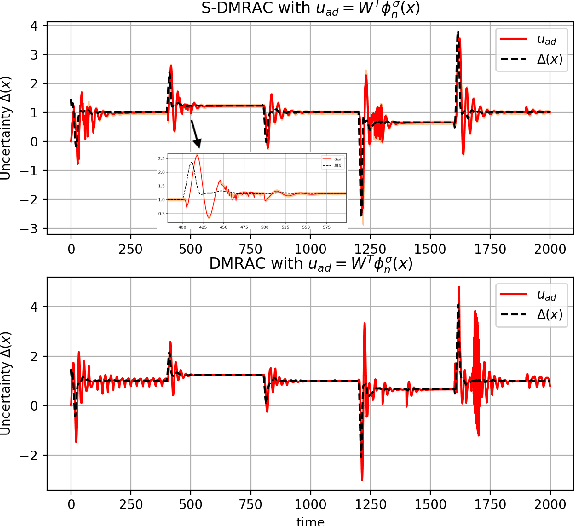
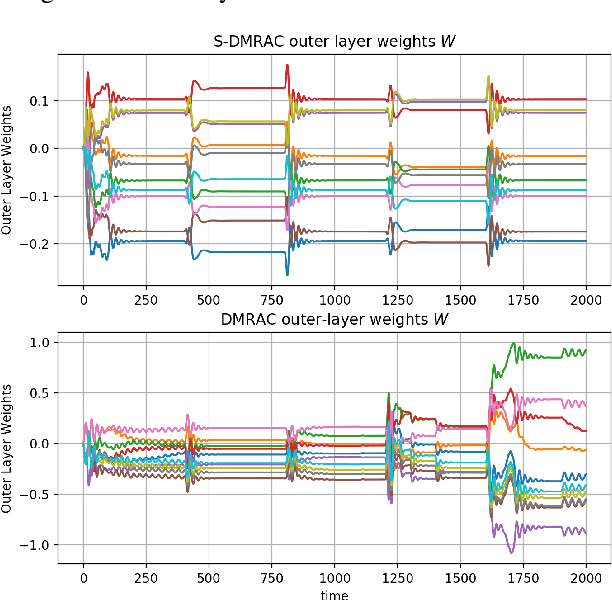
In this paper, we present a Stochastic Deep Neural Network-based Model Reference Adaptive Control. Building on our work "Deep Model Reference Adaptive Control", we extend the controller capability by using Bayesian deep neural networks (DNN) to represent uncertainties and model non-linearities. Stochastic Deep Model Reference Adaptive Control uses a Lyapunov-based method to adapt the output-layer weights of the DNN model in real-time, while a data-driven supervised learning algorithm is used to update the inner-layers parameters. This asynchronous network update ensures boundedness and guaranteed tracking performance with a learning-based real-time feedback controller. A Bayesian approach to DNN learning helped avoid over-fitting the data and provide confidence intervals over the predictions. The controller's stochastic nature also ensured "Induced Persistency of excitation," leading to convergence of the overall system signal.
Adaptive Policy Transfer in Reinforcement Learning
May 10, 2021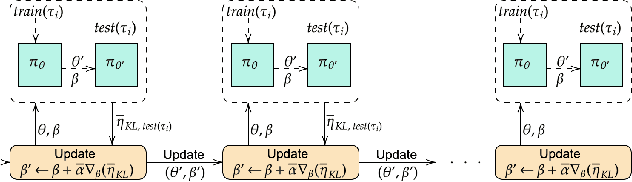
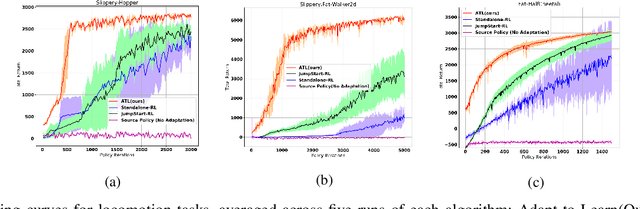
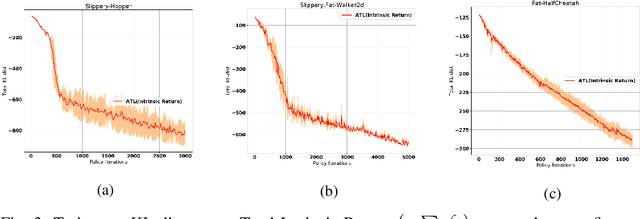
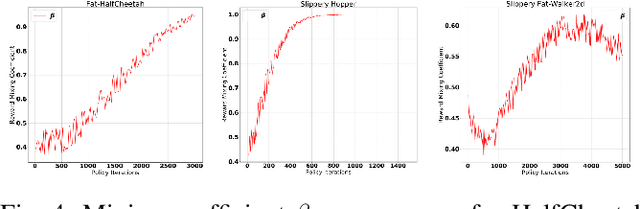
Efficient and robust policy transfer remains a key challenge for reinforcement learning to become viable for real-wold robotics. Policy transfer through warm initialization, imitation, or interacting over a large set of agents with randomized instances, have been commonly applied to solve a variety of Reinforcement Learning tasks. However, this seems far from how skill transfer happens in the biological world: Humans and animals are able to quickly adapt the learned behaviors between similar tasks and learn new skills when presented with new situations. Here we seek to answer the question: Will learning to combine adaptation and exploration lead to a more efficient transfer of policies between domains? We introduce a principled mechanism that can "Adapt-to-Learn", that is adapt the source policy to learn to solve a target task with significant transition differences and uncertainties. We show that the presented method learns to seamlessly combine learning from adaptation and exploration and leads to a robust policy transfer algorithm with significantly reduced sample complexity in transferring skills between related tasks.
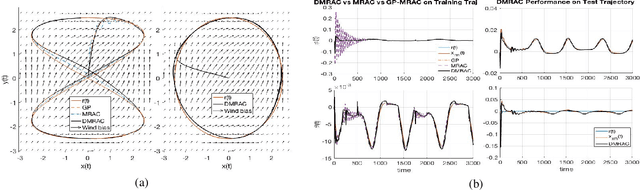
Asynchronous Deep Model Reference Adaptive Control
Nov 04, 2020



In this paper, we present Asynchronous implementation of Deep Neural Network-based Model Reference Adaptive Control (DMRAC). We evaluate this new neuro-adaptive control architecture through flight tests on a small quadcopter. We demonstrate that a single DMRAC controller can handle significant nonlinearities due to severe system faults and deliberate wind disturbances while executing high-bandwidth attitude control. We also show that the architecture has long-term learning abilities across different flight regimes, and can generalize to fly different flight trajectories than those on which it was trained. These results demonstrating the efficacy of this architecture for high bandwidth closed-loop attitude control of unstable and nonlinear robots operating in adverse situations. To achieve these results, we designed a software+communication architecture to ensure online real-time inference of the deep network on a high-bandwidth computation-limited platform. We expect that this architecture will benefit other deep learning in the closed-loop experiments on robots.
Deep Model Reference Adaptive Control
Sep 18, 2019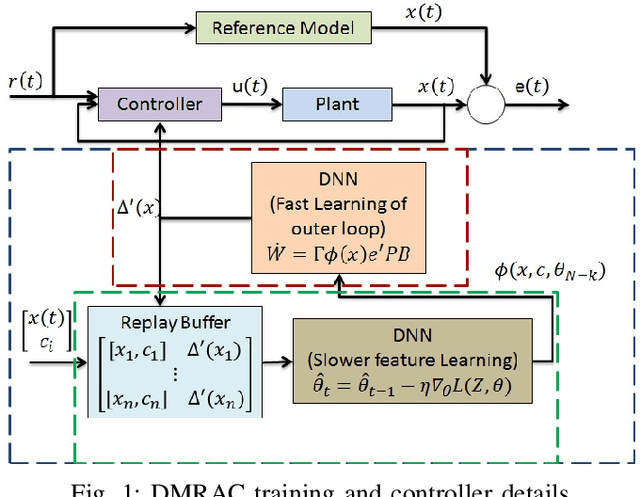
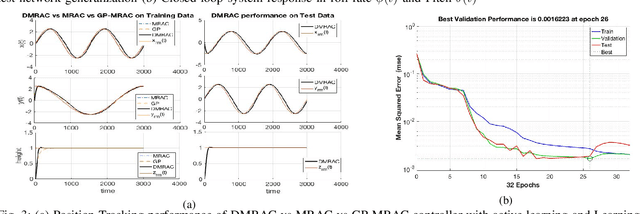
We present a new neuroadaptive architecture: Deep Neural Network based Model Reference Adaptive Control (DMRAC). Our architecture utilizes the power of deep neural network representations for modeling significant nonlinearities while marrying it with the boundedness guarantees that characterize MRAC based controllers. We demonstrate through simulations and analysis that DMRAC can subsume previously studied learning based MRAC methods, such as concurrent learning and GP-MRAC. This makes DMRAC a highly powerful architecture for high-performance control of nonlinear systems with long-term learning properties.
Cross-Domain Transfer in Reinforcement Learning using Target Apprentice
Jan 22, 2018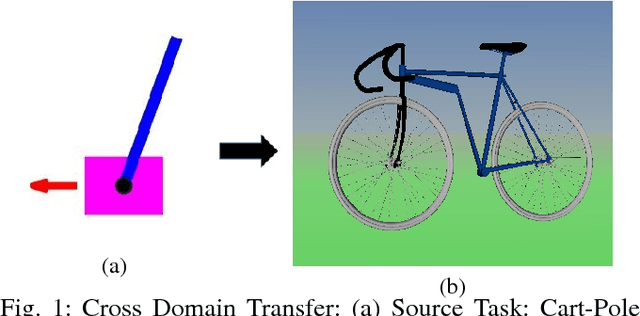
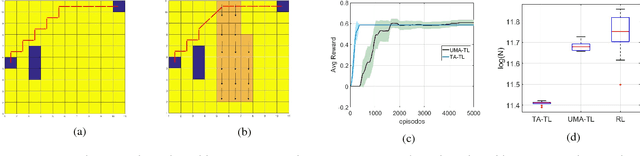
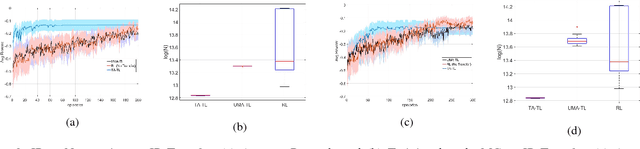
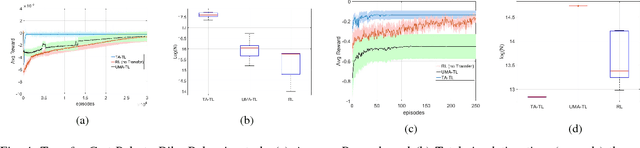
In this paper, we present a new approach to Transfer Learning (TL) in Reinforcement Learning (RL) for cross-domain tasks. Many of the available techniques approach the transfer architecture as a method of speeding up the target task learning. We propose to adapt and reuse the mapped source task optimal-policy directly in related domains. We show the optimal policy from a related source task can be near optimal in target domain provided an adaptive policy accounts for the model error between target and source. The main benefit of this policy augmentation is generalizing policies across multiple related domains without having to re-learn the new tasks. Our results show that this architecture leads to better sample efficiency in the transfer, reducing sample complexity of target task learning to target apprentice learning.